现如今,基于声音信号的海上目标识别是进行海量探测和目标识别的可靠方法,也是水声信号处理领域的重要研究内容。
项目简介
数据集
原始数据包含15类的水下音频数据,每类里面包含长度不等的一段音频数据。
目的
训练一个模型,对这15类目标进行识别分类。
思考方法
- 最开始尝试直接用语音识别的模型(
LSTM)对其分类,后来发现效果很差,考虑到可能是水下环境复杂,原始音频数据包含大量噪音。 - 于是开始考虑其他方法。最后通过查阅资料发现,在水声领域,通常可以将音频信号数据转换为谱图进行处理,于是尝试将原始音频数据先转换为谱图,再用
CNN对其进行分类识别。 CNN的方法相比于LSTM,在准确率上有所提升,但还是不够好。又考虑到原始数据由于安全保密或者是收集困难等原因,数据集数量不多,而大量的训练数据集是保证深度学习方法性能的关键。遂最终又引入了GAN网络。先对转换后的频谱做了扩充,然后再用CNN网络对其识别分类,准确率相较于仅用CNN,又有了不错的提升。
项目实现过程
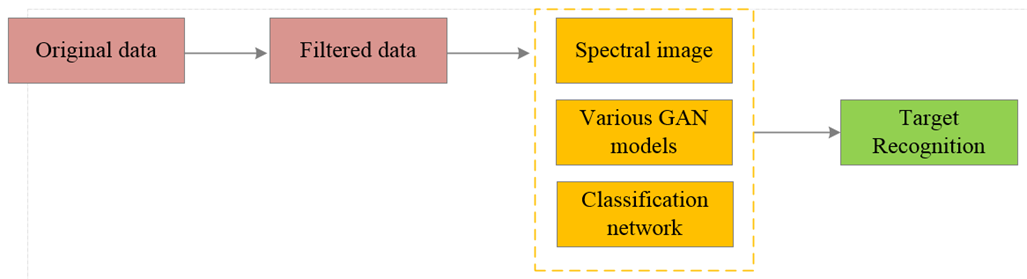
整个实现流程如下图所示
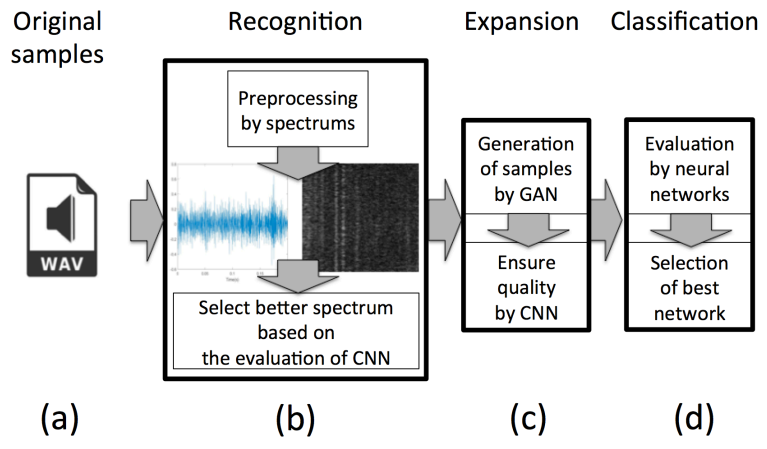
- (a)是 .wav格式的原始样本
- (b)是通过频谱进行的数据预处理和基于CNN的频谱选择,从而确保样本可以被神经网络识别。
- (c)由GAN进行数据集扩展,额外的CNN是为了确保生成频谱的质量
- (d)对网络进行评估并选择最佳网络。
数据预处理
在水声领域,常见的频谱图有很多,例如Lofar、Audio、Demon、Histogram等,我们尝试将原始音频转换为了各种谱图存储,每种谱图都包含15类。部分转换后的频谱如下图所示:
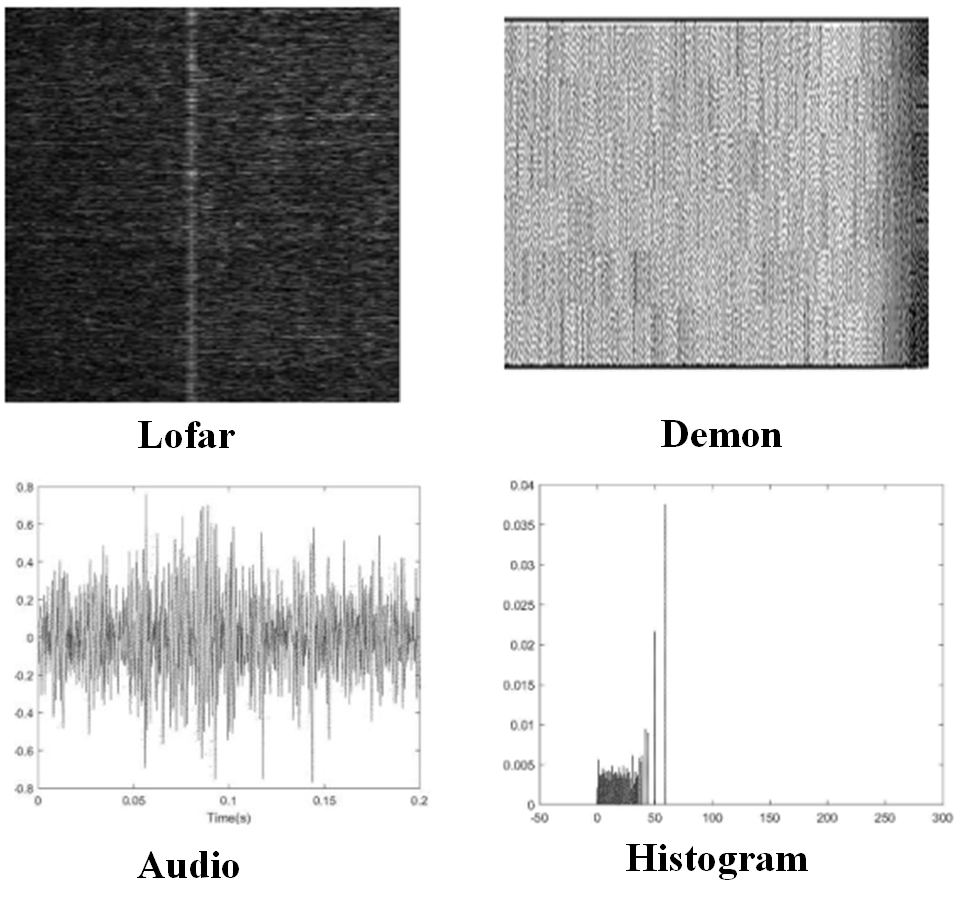
为了找到最好的频谱图,我们直接选择了AlexNet网络,针对每种转换好的频谱,为其划分好训练集和测试集,各训练了一个分类模型。通过比较在测试集上的准确率,我们发现Lofar频谱的识别率最高,于是选定它为原始音频转换后的频谱。
Lofar频谱的转换
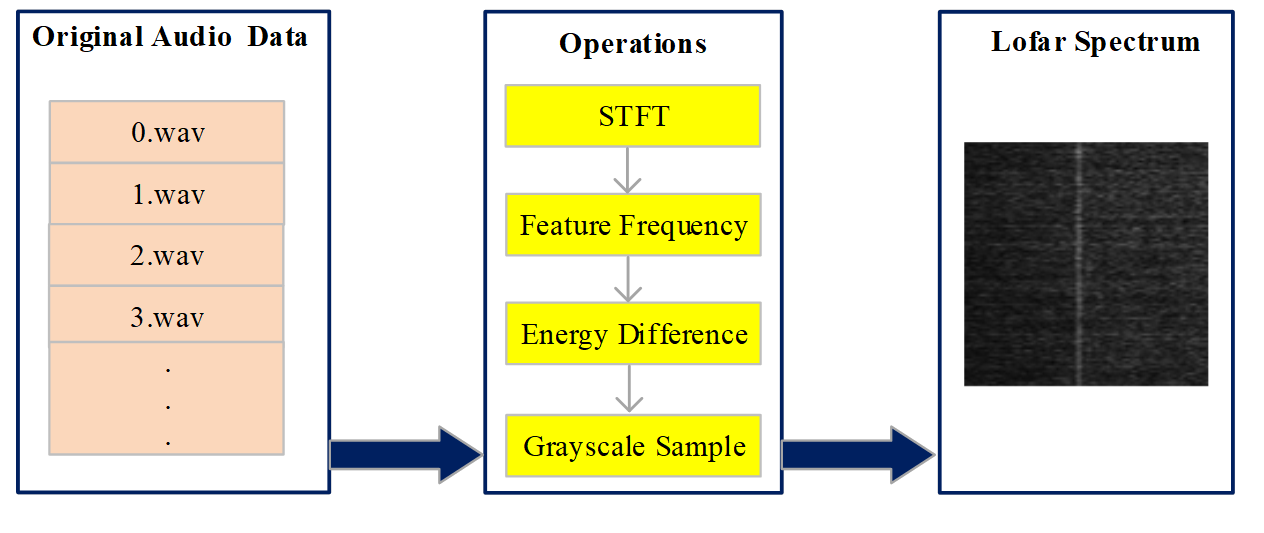
将原始音频转换为Lofar频谱,主要是通过STFT(快速傅里叶变换)实现的。
- 对于每一类的音频,对其做
STFT后,先找到具有特征的频率段, - 然后将数据根据能量差值转换为对应的灰度值,
- 每隔1s选取一段音频,重复步骤1和2,最终每类音频得到1000张灰度的
Lofar谱图
CNN网络
得到每类的Lofar频谱后,我们设计了一个CNN网络来训练分类模型。网络结构图和参数设置如下所示:
网络模型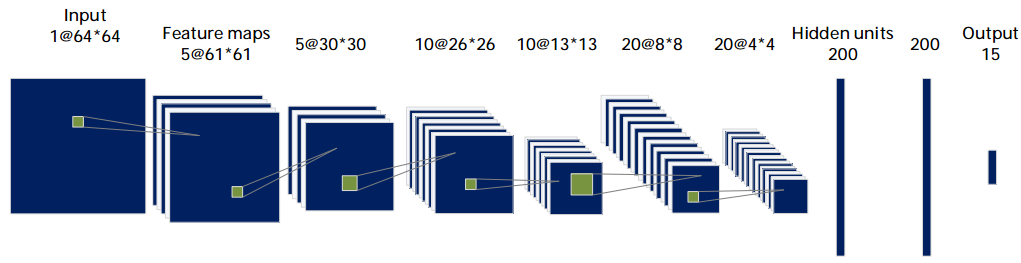
参数设置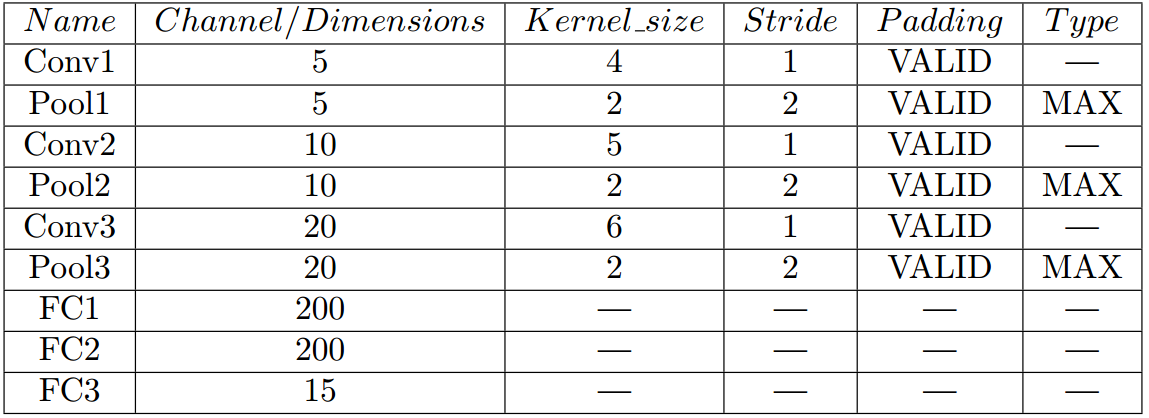
最终测试集在上述分类模型中取得了75.7%的识别率。
GAN网络
在引入GAN网络前,我们也尝试了原始的数据增广的方法,例如旋转、反转、亮度增强、添加噪音等,如下图所示,但是这些方法生成的数据都有很大的局限性,即图片缺乏多样性,训练出来的分类模型准确率基本没有提升。

原始GAN
为了进一步提升识别准确率,我们引入了GAN生成式对抗网络。生成式对抗网络主要由2部分组成:
- 生成模型G:一个二分类器,估计一个样本来自训练数据(真实)的概率。若样本来自真实数据,输出大概率值,否则输出小概率值。
- 判别模型D:捕捉生成数据的分布。用服从某一分布(均匀分布、高斯分布)的噪音向量$z$去生成一个类似真实训练数据的分布。
G要尽量最小化D的输出值,D要最大化输出值,两者相互对抗。所以原始GAN模型函数可以表示如下:
$$
\min \limits_{G}\max\limits_{D}GAN(D,G)=E_{x\sim P_{data}(x)}[logD(x)]+E_{z\sim p_z(z)}[log(1-D(G(z)))]
$$
GAN模型示意图
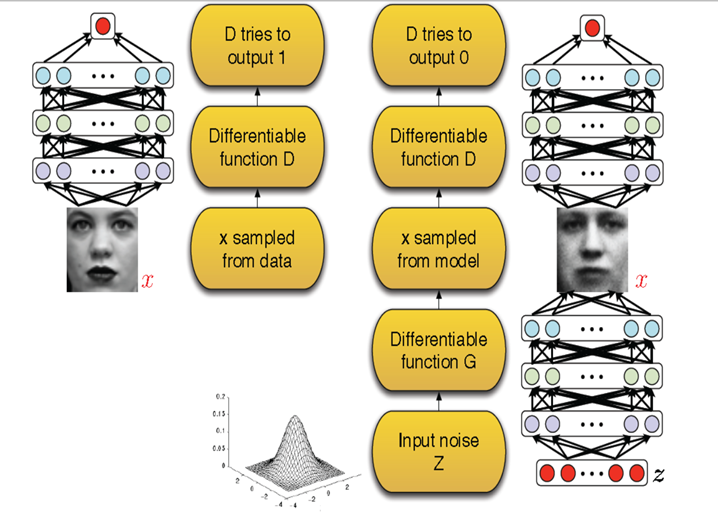
如果1用于表示实际样本,则0是假样本。 对于来自实际样本的数据,D应尽可能地输出概率值1。 对于来自世代的假样本,D应该尽量输出0的概率值。它们相互竞争并最终达到一定的稳定状态:即G的分布尽可能接近实际样本的分布。
CGAN
在本项目中,我们的数据共有15类,如果使用原始的GAN网络,我们需要针对每一个类别的Lofar谱图训练一个生成模型,这样太过麻烦。最终我们选择了CGAN网络。
CGAN网络将原始GAN网络从无监督变为有监督。生成器和判别器都增加了额外信息y为条件,y可以是任意信息,例如类别信息(标签)或者是其他模态的数据。相比于原始GAN,CGAN的模型函数可以表示如下(只是多了标签数据y):
$$
\min \limits_{G}\max\limits_{D}GAN(D,G)=E_{x\sim P_{data}(x|y)}[logD(x)]+E_{z\sim p_z(z)}[log(1-D(G(z|y)))]
$$
CGAN模型示意图
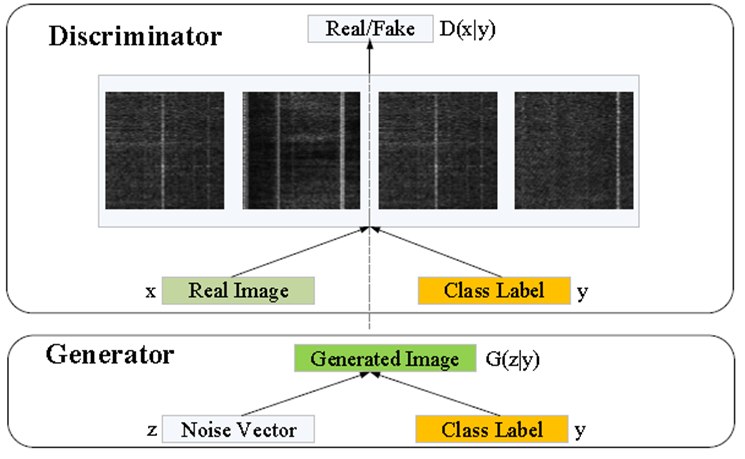
生成式模型G中,先验输入噪音$P(z)$和条件信息$y$联合组成了联合隐层表征。
CGAN网络设计
网络模型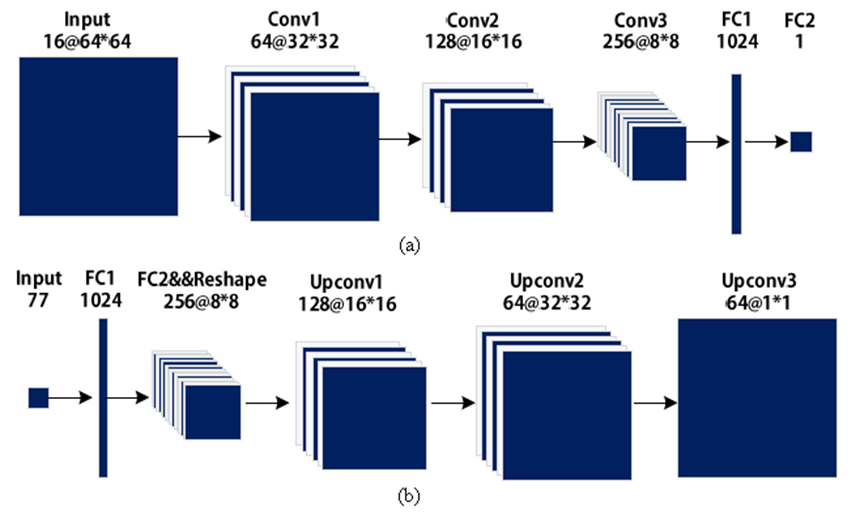
参数设置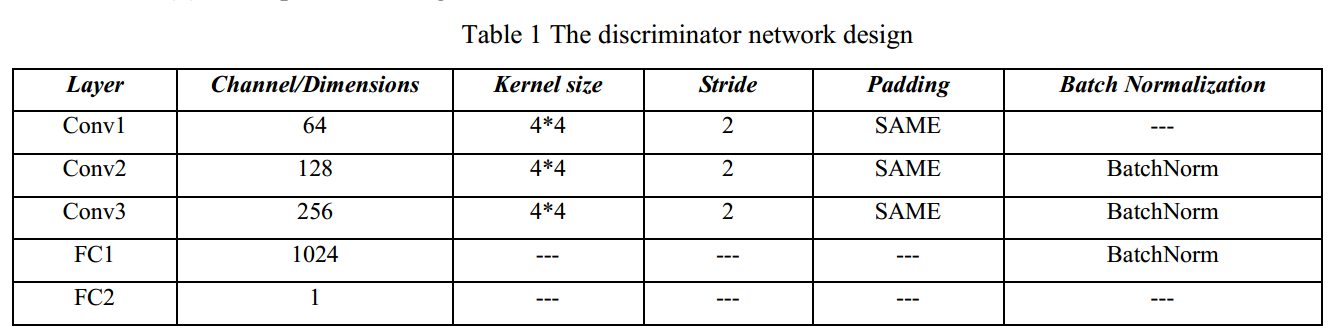
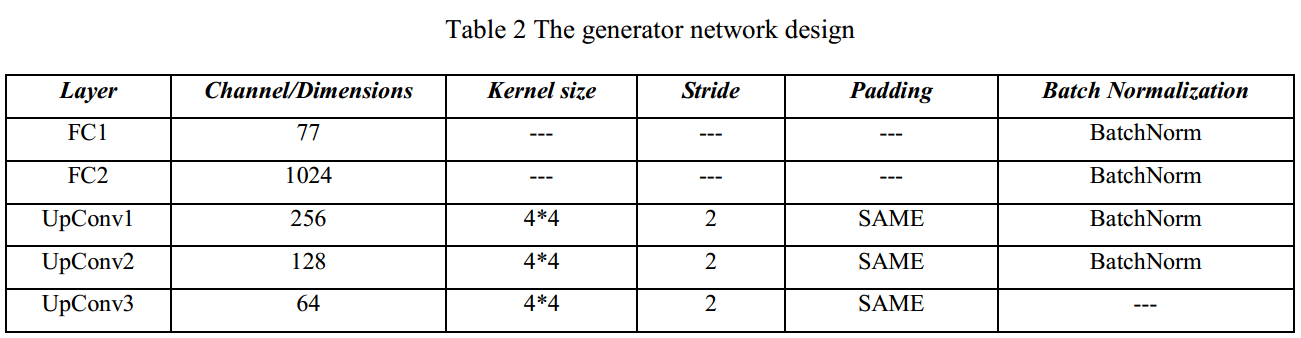
我们输入15种类型的LOFAR频谱,每种频谱包含1000个样本到设计的CGAN网络中,并且一些超参设置如下:batch_size=64,learning_rate=0.0001,epoches=40。
训练后,我们的方法可以利用G模型不仅可以生成某种特定的光谱样本,而且还能生成各种光谱样本。 在下图中展示了一些原始和生成的样本,其中(a)和(b)对应于单个类,而(c)和(d)对应于各种类。
相比之下,我们发现由我们的网络生成的数据包含共同的特征线,并且在某些情况下,所有这些特征线都清晰地显示并且具有比原始训练样本更突出的特征线。

除此之外,我们也对原始样本和该图中生成的样本之间进行了更深入和更详细的比较。最后,我们可以发现生成的样本具有丰富的多样性,其中包含与(a)中的原始样本相似的样本,以及包括具有一定噪声的样本,并且所有上述样本都在(b)中示出。
(b)中的顶部样本与原始样本类似,底部包含一些噪声,但都具有明显的光谱特征。 使用生成的样本作为训练数据可以极大地改善训练样本的多样性,从而在一定程度上避免过度拟合问题。
图像质量验证
上面只是通过观察得到的结果,为了进一步验证我们的网络生成的样本是高质量的,我们使用G模型为每个类生成3000个样本,然后将它们与原始样本混合并进入AlexNet分类网络进行训练。主要进行了以下实验:
- 我们的方法使用80%的原始样本进行训练,并验证剩余的20%。
- 同时,我们还应用上述模型对15种类型的生成样本进行分类和识别。
- 此外,我们将原始样本和生成样本混合,其中80%用于训练,其余20%用于验证。
实验结果如下所示:
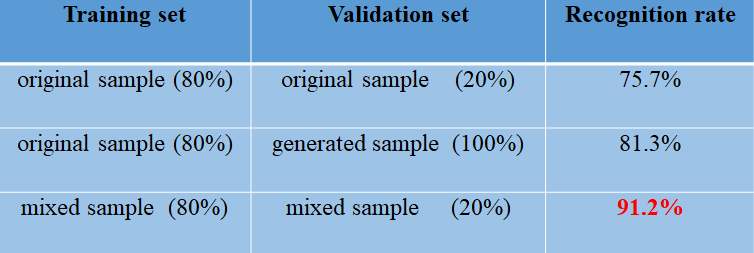
上述实验表明混合数据所获得的性能比仅用原始数据集训练的性能高出15%以上。这证明了我们的CGAN网络可以生成高质量的lofar谱,从而解决了水声信号领域数据样本不足的问题。生成的谱图可以用于提高水声信号分类和识别任务的准确性和稳定性。
CNN网络选取
确定了生成的样本具有较高的质量后,我们用G模型为每类Lofar谱图生成了3000个样本,除了将其输入到我们设计的CNN网络之外,我们也和其他的一些CNN网络(LeNet、AlexNet、VGG16)做了对比,最终我们的设计的网络模型识别率较高。
拓展
如果希望再进一步提升识别率,可以从以下2方面做出改进:
- 其他的GAN模型。CGAN只是使用了真实图片的类别信息,可以考虑其他的衍生GAN模型,例如InfoGAN WGAN WGAN-GP BEGAN……,也许能生成质量更高的样本
- 去噪。水下环境复杂,原始的音频数据包含较多的噪音。可以考虑先对原始数据进行去噪,得到高质量数据后,再转换为谱图用CNN分类
当然,也可以把上述2点结合,先去噪,再尝试其他的GAN模型,也许能得到更好的结果。
