项目简介
现有的去噪方法取决于噪声类型的信息,通常由专家分类。换句话说,那些方法没有应用计算方法来对图像噪声类型进行预分类。此外,这些方法假设图像的噪声类型是像高斯噪声那样的单类噪声类型,这限制了实际应用中去噪方法的选择和能力。
与现有方法不同,我们采用一种新框架,不仅可以对单一类型噪声进行分类和去噪,而且可以根据实际需要对混合类型的噪声进行分类和去噪。
我们的方法和现有方法对比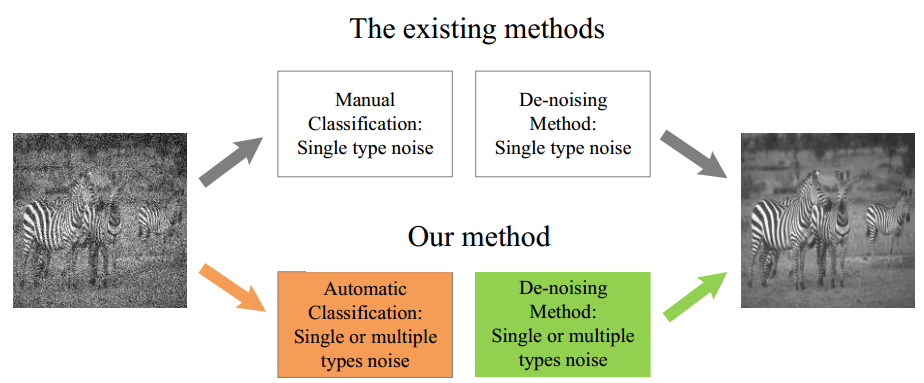
数据集
Mnist:Subset(10000张)cifar10:Subset(10000张)BSD500:Fullset(500张)
方法
设计一个包含2个网络的框架:噪音分类网络 去噪网络。
- 噪音分类网络:对图像所包含的噪音类型进行识别分类
- 去噪网络:根据噪音分类网络判别的噪音类型选择相应的去噪模型去除噪音,进而得到干净图像
总体框架图如下所示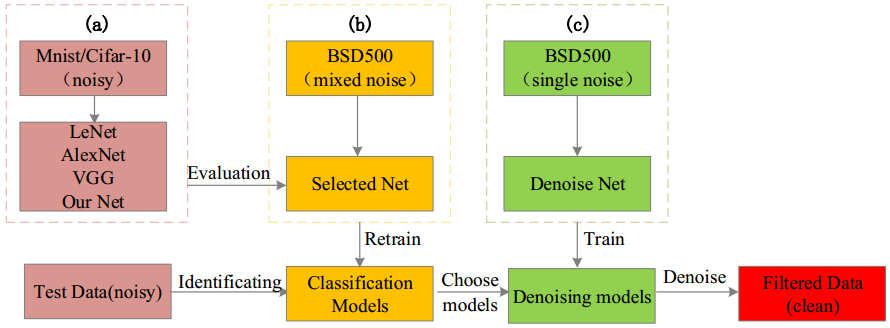
项目实现过程
数据预处理
针对原始BSD500数据集,对其进行灰度转换,得到它的灰度图。
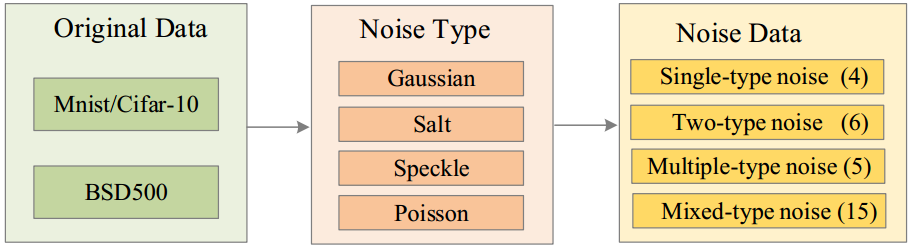
对于Mnist(gray)、Cifar10(RGB)、BSD500(Gray&RGB)这4个数据集,在每个数据集上添加Gaussian、Salt、Speckle、Poisson噪音(可以组合),最终得到
- 单类噪音数据集4类:Ga,Sa,Sp ,Po
- 两类噪音数据集6类:Ga&Sa,Ga&Sp,Ga&Po,Sa&Sp,Sa&Po,Sp&Po
- 多类噪音数据集5类(3和4):Ga&Sa&Sp,Ga&Sa&Po,Ga&Sp&Po,Sa&Sp&Po, Ga&Sa&Sp&Po
- 混合噪音数据集共15类:综合上述1,2,3
噪音分类网络
网络模型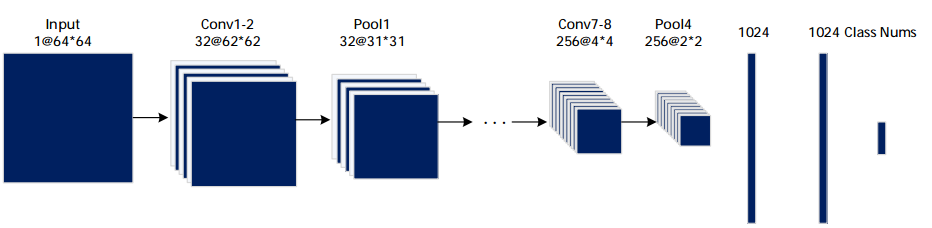
详细参数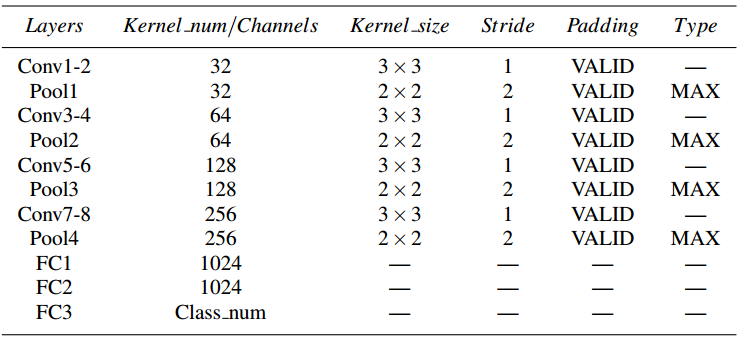
利用Mnist和Cifar10的噪音数据集,对比几个分类网络,筛选出噪音识别准确率最高的网络(Our)。
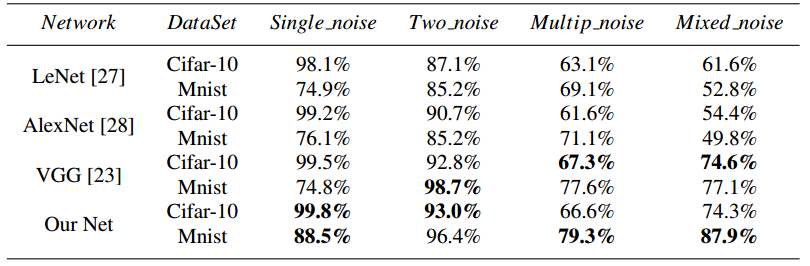
为了和去噪网络的数据集匹配,将BSD的混合噪音也输入了我们设计的CNN网络,训练了一个分类模型。结果如下:

去噪网络设计
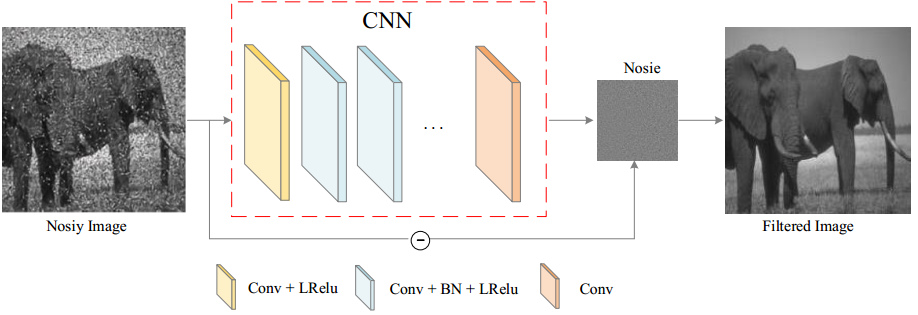
去噪网络主要由三种类型的层组成,如上图所示,由三种不同的颜色表示。
- 在第一层,我们使用96个尺寸的3×3×c滤波器进行卷积并生成96个特征图,我们在输入到下一层时使用整流线性单元的变量LReLU 来实现非线性。 这里,c表示训练图像的通道数,c表示灰度1,c表示彩色图3。
- 从第2层到第(d-1)层,使用96个尺寸为3×3×96的滤波器 并且还使用了LReLU,并在卷积层和LReLU层之间进行了批量归一化操作,从而可以提高训练速度并加快收敛过程。
- 对于最后一层,它使用大小为3×3×96的c滤波器重建输出。 它还删除了所有下采样层,因为这会大大降低我们模型的去噪效果。
把BSD500的8种单类噪音(Gray和RGB各4种)数据输入设计的去噪网络,得到了8个单类噪音去噪模型。
测试:
- 如果图片被分类网络识别出仅包含单类噪音,就选择相应的单类去噪模型去除噪音
- 如果图片被分类网络识别出包含多种噪音,根据所包含的噪音类型,依次选择多个单类去噪模型去除噪音
去噪结果分析
去噪好坏的评价标准
- PSNR(Peak Signal to Noise Ratio)峰值信噪比
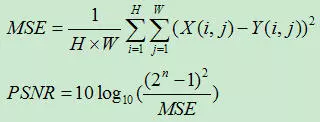
其中,MSE表示当前图像X和参考图像Y的均方误差(Mean Square Error),H、W分别为图像的高度和宽度;n为每像素的比特数,一般取8,即像素灰阶数为256.。PSNR的单位是dB,数值越大表示失真越小越好。PSNR是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。为此我们还引入了下面一个评价指标
- SSIM(structural similarity)结构相似性。它分别从亮度、对比度、结构三方面度量图像相似性。
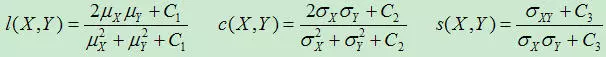
其中$\mu_X$、$\mu_Y$分别表示图像$X$和$Y$的均值,$\sigma_X$、$\sigma_Y$分别表示图像$X$和$Y$的方差,$\sigma_{XY}$表示图像$X$和$Y$的协方差,即
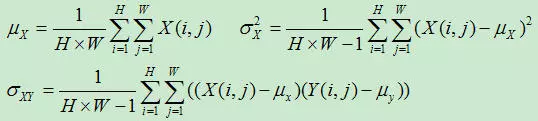
$C_1$、$C_2$、$C_3$为常数,为了避免分母为0的情况,通常取$C_1=(K_1 \times L)^2$, $C2=(K_2 \times L)^2$, $C_3=C_2/2$, 一般地$K_1=0.01$,$K_2=0.03$, $L=255$, 则
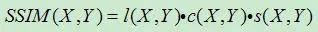
SSIM取值范围[0,1],值越大,表示图像失真越小越好。
单类噪音


与其它方法的对比

两类噪音


多类噪音



总结
- 在单类噪音上取得了不错的效果,彩色图要比灰度图的去噪效果好,而且比已有的方法要好。
- 多类噪音去噪效果不够好,灰度图要比彩色图好。
