神经网络算法( Neural Network )是机器学习中非常非常重要的算法。它 以人脑中的神经网络为启发,是整个深度学习的核心算法。深度学习就是根据神经网络算法进行的一个延伸。
背景
神经网络是受神经元启发的,对于神经元的研究由来已久,1904年生物学家就已经知晓了神经元的组成结构。一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。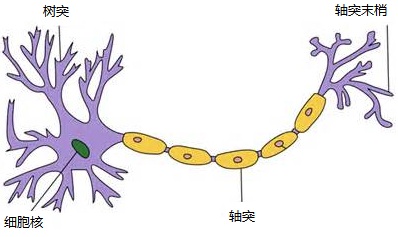
- 1949年心理学家Hebb提出了Hebb学习率,认为人脑神经细胞的突触(也就是连接)上的强度上可以变化的。于是计算科学家们开始考虑用
调整权值的方法来让机器学习。这为后面的学习算法奠定了基础。- 1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字–
感知器( Perceptron )。- 1986年,Rumelhar和Hinton等人提出了
反向传播( Backpropagation ,BP)算法,这是最著名的一个神经网络算法。
组成
多层神经网咯主要由三部分组成:输入层(input layer), 隐藏层 (hidden layers), 输入层 (output layers)。
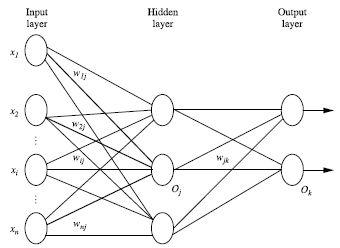
每层由单元(units)组成, 输入层(input layer)是由训练集的实例特征向量传入,经过连接结点的权重(weight)传入下一层,一层的输出是下一层的输入。 隐藏层(hidden layers)的个数可以是任意的,输入层有一层,输出层(output layers)有一层。每个单元(unit)也可以被称作神经结点。上图为2层的神经网络(一般输入层不算)。
一层中加权的求和,然后根据非线性方程转化输出。作为多层向前神经网络,理论上,如果有足够多的隐藏层(hidden layers) 和足够大的训练集, 可以模拟出任何方程。
神经网络可以用来解决分类(classification)问题,也可以解决回归( regression )问题。
单层到多层的神经网络
由两层神经网络构成了单层神经网络,它还有个别名——— 感知机(Perceptron)。
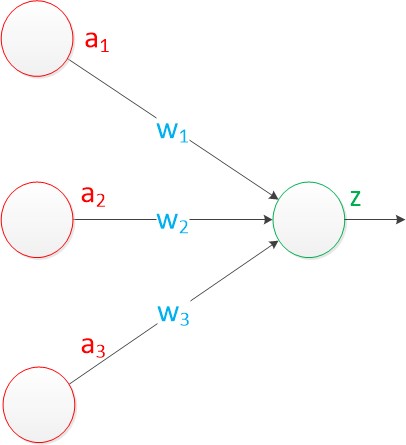
上图中,有3个输入,连接线的权值分别是 w1, w2, w3。将输入与权值进行乘积然后求和,作为 z单元的输入,如果 z 单元是函数 g ,那么就有 z = g(a1 * w1 + a2 * w2 + a3 * w3) 。
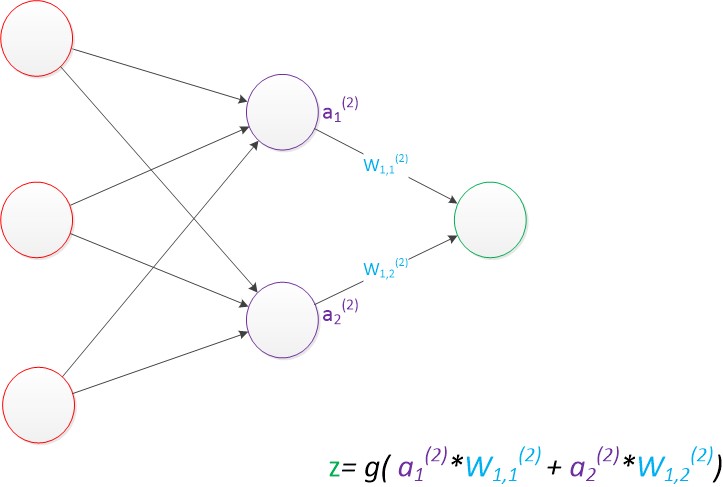
单层神经网络的扩展(2个z单元),也是一样的计算方式:
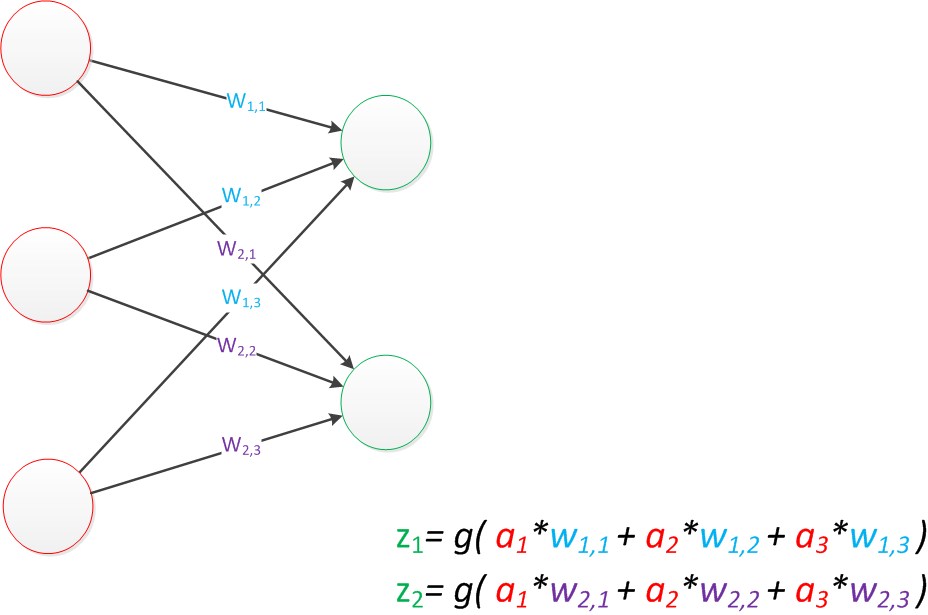
在多层神经网络中,只不过是将输出作为下一层的输入,一样是乘以权重然后求和:
设计
在使用神经网络训练数据之前,必须确定神经网络的层数以及每层单元的个数。特征向量在被传入输入层时通常被先标准化(normalize)到0和1之间 (为了加速学习过程)。
离散型变量可以被编码成每一个输入单元对应一个特征值可能赋的值
例如:特征值A可能取三个值($a_0, a_1, a_2$), 可以使用3个输入单元来代表A。
- 如果$A=a_0$, 那么代表$a_0$的单元值就取1,其他取0,[1, 0, 0]
- 如果$A=a_1$, 那么代表$a_1$的单元值就取1,其他取0,[0, 1, 0]
- 如果$A=a_2$, 那么代表$a_2$的单元值就取1,其他取0,[0, 0, 1]
对于分类问题,如果是2类,可以用一个输出单元表示(0和1分别代表2类)。如果多余2类,每一个类别用一个输出单元表示,所以输入层的单元数量通常等于类别的数量。
一般没有明确的规则来设计最好有多少个隐藏层,通常是根据实验测试和误差,以及准确度来实验并做出改进。
交叉验证
模型训练结束后,如何来衡量我们模型的泛化能力(测试集上准确率)呢?常见的方法是将数据集分为两类,训练集和测试集,利用测试集的数据将模型的预测结果与真实测试标签作对比,得出准确度。下面介绍另一个常用但更科学的方法———交叉验证方法( Cross-Validation )。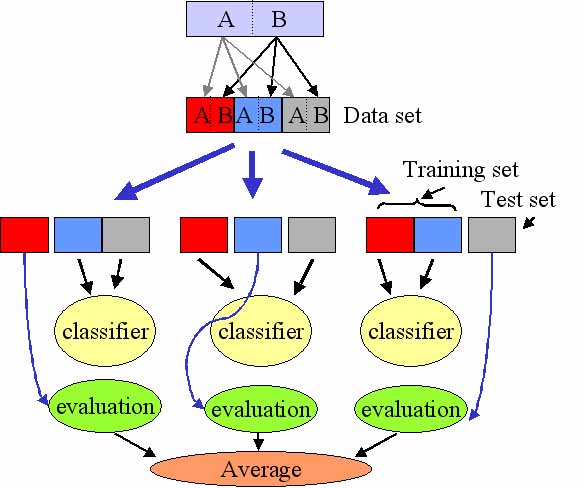
这个方法不局限于将数据集分成两份。如上图所示,我们可以将原始数据集分成 k 份。第一次用第一份作为训练集,其余作为测试集,得出这一部分的准确度 ( evaluation )。第二次再用第二份作为训练集,其余作为测试集,得出这第二部分的准确度。以此类推,最后取各部分准确度的平均值作为最终的模型衡量指标。
BP算法
BP 算法 (BackPropagation )是多层神经网络的训练一个核心的算法。目的是更新每个连接点的权重,从而减小预测值(predicted value )与真实值 ( target value )之间的差距。输入一条训练数据就会更新一次权重,反方向(从输出层=>隐藏层=>输入层)来以最小化误差(error)来更新权重(weitht)。
在训练神经网络之前,需要初始化权重(weights )和偏向( bias ),初始化是随机值, -1 到 1 之间或者-0.5到0.5之间,每个单元有一个偏向。
BP算法有2个过程,前向传播和反向传播,后者是关键。我们以下图为例,分析BP算法的整个过程。
前向传播
利用上一层的输入,得到本层的输入:
$$
I_j = \sum_{i}w_{i,j}O_{i} + \theta_{j}
$$
其中$w_{i,j}$表示权重,$O_{j}$表示当前神经单元的值,$\theta_{j}$为当前神经单元的偏置向。$i=0$时,$O_{j}$即为输入单元的值。
得到输入值后,神经元要怎么做呢?我们先将单个神经元进行展开如图:
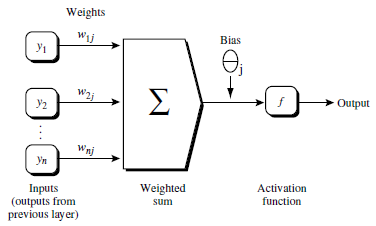
隐藏层单元得到值后进行累加求和,然后需要进行一个非线性转化,这个转化在神经网络中称为激活函数( Activation function ),这个激活函数是一个 S(下面会有所介绍) 函数,图中以 f 表示,它的函数为:
$$
O_{j} = \frac{1}{1+e^{-I_j}}
$$
反向传播
前向传播结束后,我们要计算误差,然后根据误差(error)反向传送,更新权重和偏置向。
对于输出层的误差:
$$
Err_{j} = O_{j}(1-O_{j})(T_{j}-O_{j})
$$
其中$O_{j}$表示预测值,$T_{j}$表示真实值。
对于隐藏层的误差:
$$
Err_{j} = O_{j}(1-O_{j})\sum_{k}Err_{k}w_{j,k}
$$
其中$Err_{k}$为后层单元误差,$w_{j,k}$为当前单元与后层单元的权重值。
更新权重:
$$
\Delta w_{i,j} = (l)Err_{j}O_{i}
$$
$$
w_{i,j} = w_{i,j} + \Delta w_{i,j}
$$
更新偏置向:
$$
\Delta\theta{j} = (l)Err_{j}
$$
$$
\theta{j} = \theta_{j} + \Delta\theta_{j}
$$
上面$(l)$为学习率
终止条件
- 权重的更新低于某个阈值,这个阈值是可以人工指定的;
- 预测的错误率低于某个阈值;
- 达到预设一定的循环次数。
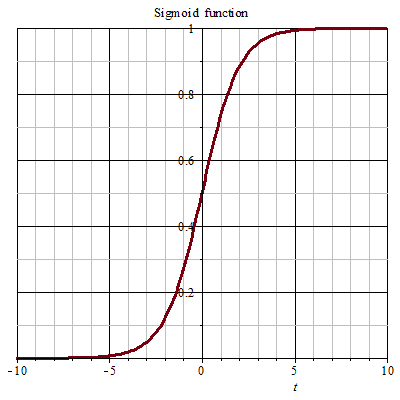
S型函数(sigmod)
神经元在对权重进行求和后,需要进行一个非线性转化,即作为参数传入激活函数去。这个激活函数是一个 S 型函数(Sigmoid)。S 函数不是指某个函数,而是一类函数,详解可参考 https://zh.wikipedia.org/wiki/S函数 。下面有两个常见的S 函数:
- 双曲函数(
tanh)- 逻辑函数(
logistic function)
Sigmod函数
S 曲线函数可以将一个数值转为值域在 0 到 1 之间,广义上S 函数是满足y值在某个值域范围内渐变的一条曲线。
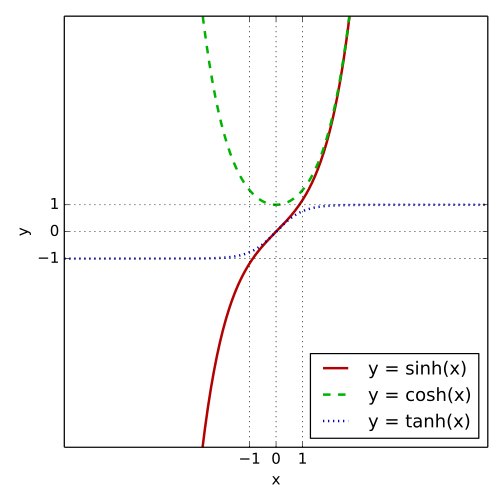
双曲函数(
tanh) 双曲函数是一类与常见的三角函数(也叫圆函数)类似的函数。详见https://zh.wikipedia.org/wiki/双曲函数 。
$$
tanhx = \frac{sinhx}{coshx}
$$
导数为
$$
\frac{d}{dx}tanhx = 1 - tanh^2x =sech^2x = \frac{1}{cosh^2x}
$$
逻辑函数(
logistic function) 逻辑函数或逻辑曲线是一种常见的S函数,详见https://zh.wikipedia.org/wiki/逻辑函数 。
一个常见的逻辑函数可以表示如下:
$$
f(x) = \frac{1}{1 + e^{-x}}
$$
导数为
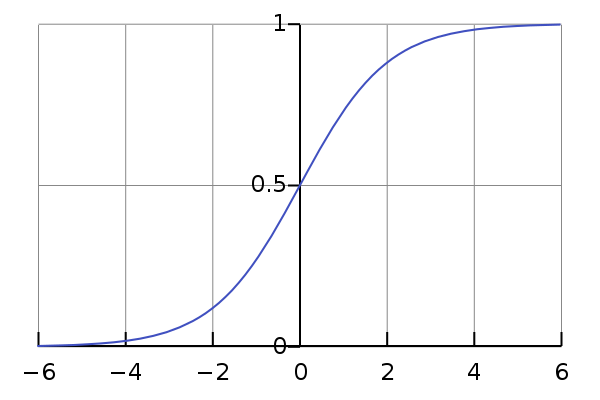
$$
\frac{d}{dx} = \frac{e^x}{(1+e^x)^2} = f(x)(1 - f(x))
$$
BP算法举例
假设有一个两层的神经网络,结构,权重和数据集如下: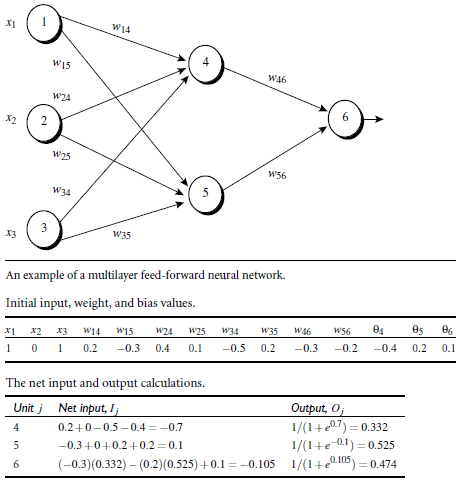
根据上述公式(3)到(8)计算误差和更新权重: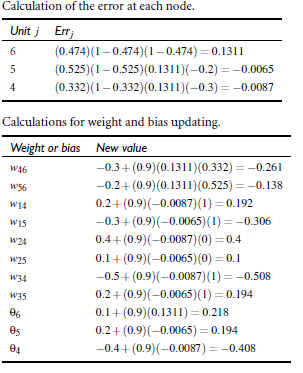
代码实例(手写数字识别)
基础函数
根据神经网络原理,代码实现一个完整的神经网络来对手写数字图片分类。(完整代码见附录)
根据上面的sigmoid 函数以及其求导得到对应的python代码:1
2
3
4
5
6
7
8
9
10
11
12def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1.0 / (1 + np.exp(-x))
def logistic_deriv(x):
fx = logistic(x)
return fx * (1 - fx)
网络函数
在网络函数中,需要确定神经网络的层数,每层的个数,从而确定单元间的权重规格和单元的偏向。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def __init__(self, layers, activation='logistic'):
if activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
elif activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_deriv
# 初始化随即权重
self.weights = []
# len(layers)layer是一个list[2,2,1],则len(layer)=3
# 除了输出层,其它层层之间的单元都要赋予一个随机产生的权重
for i in range(len(layers) - 1):
tmp_weights = (np.random.random([layers[i], layers[i + 1]]) * 2 - 1) * 0.25
self.weights.append(tmp_weights)
#初始化偏置向
#除了输入层,其它层单元都有一个偏置向
self.bias = []
for i in range(1, len(layers)):
tmp_bias = (np.random.random(layers[i]) * 2 - 1) * 0.25
self.bias.append(tmp_bias)
其中,layers 参数表示神经网络层数以及各个层单元的数量,例如下图这个模型:
上述网络模型就对应了 layers = [4, 3, 2] 。这是一个 2 层,即len(layers) - 1层的神经网络。输入层 4 个单元,其他依次是 3 ,2 。权重是表示层之间单元与单元之间的连接。因此权重也有 2 层。第一层是一个4 x 3的矩阵,即layers[0] x layers[1]。同理,偏向也有 2 层,第一层个数 3 ,即leyers[1] 。
利用np.random.random([m, n]) 来创建一个 m x n 的矩阵。在这个神经网络的类中,初始化都随机-0.25 到 0.25之间的数。
训练函数
在神经网络的训练中,需要先设定一个训练的终止条件,前面介绍了3种停止条件,这边使用的是 达到预设一定的循环次数 。每次训练是从样本中随机挑选一个实例进行训练,将这个实例的预测结果和真实结果进行对比,再进行反向传播得到各层的误差,然后再更新权重和偏向:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40def fit(self, X, y, learning_rate=0.2, epochs=10000):
#X:数据集,确认是二维,每行是一个实例,每个实例有一些特征值
X = np.atleast_2d(X)
#每个实例的标签
y = np.array(y)
# 随即梯度
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]] # 随即取某一条实例
'''
#正向传播计算各单元的值
#np.dot代表两参数的内积,x.dot(y) 等价于 np.dot(x,y)
#即a与weights内积加上偏置求和,之后放入非线性转化function求下一层
#a输入层,append不断增长,完成所有正向计算
'''
for j in range(len(self.weights)):
a.append(self.activation(np.dot(a[j], self.weights[j]) + self.bias[j] ))
# 计算错误率,y[i]真实标记 ,a[-1]预测的classlable
errors = y[i] - a[-1]
# 计算输出层的误差,根据最后一层当前神经元的值,反向更新
deltas = [errors * self.activation_deriv(a[-1]) ,] # 输出层的误差
# 反向传播,对于隐藏层的误差,从后往前
for j in range(len(a) - 2, 0, -1):
tmp_deltas = np.dot(deltas[-1], self.weights[j].T) * self.activation_deriv(a[j])
deltas.append(tmp_deltas)
#reverse将deltas的层数跌倒过来
deltas.reverse()
# 更新权重
for j in range(len(self.weights)):
layer = np.atleast_2d(a[j])
delta = np.atleast_2d(deltas[j])
self.weights[j] += learning_rate * np.dot(layer.T, delta)
# 更新偏向
for j in range(len(self.bias)):
self.bias[j] += learning_rate * deltas[j]
其中参数 learning_rate 表示学习率, epochs 表示设定的循环次数。
预测函数
预测就是将测试实例从输入层传入,通过正向传播,最后返回输出层的值:1
2
3
4
5
6#预测
def predict(self, x):
a = np.array(x) # 确保x是 ndarray 对象
for i in range(len(self.weights)):
a = self.activation(np.dot(a, self.weights[i]) + self.bias[i])
return a
手写数字图片识别
手写数字数据集来自 sklearn ,其中由1797个图像组成,其中每个图像是表示手写数字的 8x8 像素图像:
可以推出,这个神经网络的输入层将有 64 个输入单元,分类结果是 0-9 ,因此输出层有10个单元,构造为:
1 | nn = NeuralNetwork(layers=[64, 100, 10]) |
导入数据集并拆分为训练集和测试集
1 | digits = datasets.load_digits() #导入数据 |
训练并测试模型1
2
3
4
5
6
7
8
9
10
11nn.fit(X_train, labels_train)
# 收集测试结果
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i] )
predictions.append(np.argmax(o))
# 打印对比结果
print (confusion_matrix(y_test, predictions) )
print (classification_report(y_test, predictions))
程序运行结果如下:
混淆矩阵中,对角线计数越大表示该类别预测越准确,最后预测准确率在95%。
1 | [[53 0 0 0 0 0 0 0 0 0] |
附录(完整代码)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import confusion_matrix, classification_report
'''
一些激活函数及其导数的计算定义
'''
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1.0 / (1 + np.exp(-x))
def logistic_deriv(x):
fx = logistic(x)
return fx * (1 - fx)
#构建神经网络类
class NeuralNetwork:
'''
根据类实例化一个函数,_init_代表的是构造函数
self相当于java中的this
layers:一个列表,包含了每层神经网络中有几个神经元,至少有两层,输入层不算作
[, , ,]中每个值代表了每层的神经元个数
activation:激活函数可以使用tanh 和 logistics,不指明的情况下就是logistics函数
'''
def __init__(self, layers, activation='logistic'):
if activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
elif activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_deriv
# 初始化随即权重
self.weights = []
# len(layers)layer是一个list[2,2,1],则len(layer)=3
# 除了输出层,其它层层之间的单元都要赋予一个随机产生的权重
for i in range(len(layers) - 1):
tmp_weights = (np.random.random([layers[i], layers[i + 1]]) * 2 - 1) * 0.25
self.weights.append(tmp_weights)
#初始化偏置向
#除了输入层,其它层单元都有一个偏置向
self.bias = []
for i in range(1, len(layers)):
tmp_bias = (np.random.random(layers[i]) * 2 - 1) * 0.25
self.bias.append(tmp_bias)
def fit(self, X, y, learning_rate=0.2, epochs=10000):
#X:数据集,确认是二维,每行是一个实例,每个实例有一些特征值
X = np.atleast_2d(X)
#每个实例的标签
y = np.array(y)
# 随即梯度
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]] # 随即取某一条实例
'''
#正向传播计算各单元的值
#np.dot代表两参数的内积,x.dot(y) 等价于 np.dot(x,y)
#即a与weights内积加上偏置求和,之后放入非线性转化function求下一层
#a输入层,append不断增长,完成所有正向计算
'''
for j in range(len(self.weights)):
a.append(self.activation(np.dot(a[j], self.weights[j]) + self.bias[j] ))
# 计算错误率,y[i]真实标记 ,a[-1]预测的classlable
errors = y[i] - a[-1]
# 计算输出层的误差,根据最后一层当前神经元的值,反向更新
deltas = [errors * self.activation_deriv(a[-1]) ,] # 输出层的误差
# 反向传播,对于隐藏层的误差,从后往前
for j in range(len(a) - 2, 0, -1):
tmp_deltas = np.dot(deltas[-1], self.weights[j].T) * self.activation_deriv(a[j])
deltas.append(tmp_deltas)
#reverse将deltas的层数跌倒过来
deltas.reverse()
# 更新权重
for j in range(len(self.weights)):
layer = np.atleast_2d(a[j])
delta = np.atleast_2d(deltas[j])
self.weights[j] += learning_rate * np.dot(layer.T, delta)
# 更新偏向
for j in range(len(self.bias)):
self.bias[j] += learning_rate * deltas[j]
#预测
def predict(self, x):
a = np.array(x) # 确保x是 ndarray 对象
for i in range(len(self.weights)):
a = self.activation(np.dot(a, self.weights[i]) + self.bias[i])
return a
if __name__ == "__main__":
'''
手写体数字图片识别,每张图片像素大小为8*8,共(0-9)10类
调用NeuralNetwork类并设置layer参数:
输入层64个单元,隐藏层100个单元,输出层单元数为类别数10
'''
nn = NeuralNetwork(layers=[64, 100, 10])
digits = datasets.load_digits() #导入数据
X = digits.data
y = digits.target
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 分类结果离散化
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
nn.fit(X_train, labels_train)
# 收集测试结果
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i] )
predictions.append(np.argmax(o))
# 打印对比结果
print (confusion_matrix(y_test, predictions) )
print (classification_report(y_test, predictions))
