线性回归(linear regression)是利用数理统计和归回分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。与之前的分类问题( Classification )不一样的是,分类问题的结果是离散型的;而回归问题中的结果是连续型(数值)的。
数据特征
数理统计中,常用的描述数据特征的有:
- 均值(mean):又称平均数或平均值,是计算样本中算术平均数:
$$
\overline{x} = \frac{\sum_{i=1}^{n}x_i}{n}
$$中位数(median):将数据中的各个数值按照大小顺序排列,居于中间位置的变量。当n为基数的时候:直接取位置处于中间的变量;当n为偶数的时候,取中间两个量的平均值。
众数(mode):数据中出现次数最多的数。
方差( variance ):一种描述离散程度的衡量方式:
$$
s^2 = \frac{\sum_{i=1}^{n}(x_{i}-\overline{x})^2}{n-1}
$$
- 标准差 (standard deviation) :将方差$s^2$开方就能得到标准差。
简单线性回归
算法
简单线性回归(Simple Linear Regression ),,也就是一元线性回归,包含一个自变量x 和一个因变量y 。常被用来描述因变量(y)和自变量(X)以及偏差(error)之间关系的方程叫做回归模型,这个模型是:
$$
y = \beta_0 + \beta_1x + \epsilon
$$
其中偏差 $\epsilon$ 满足正态分布的。因此它的期望值是 0 。 $\epsilon$ 的方差(variance)对于所有的自变量 x 是一样的。
等式两边求期望可得:
$$
E(y) = \beta_0 + \beta_1x
$$
其中,β0 是回归线的截距,β1 是回归线的斜率,E(y) 是在一个给定 x 值下 y 的期望值(均值)。
假设我们的估值函数(注意,是估计函数):
$$
\widehat{y} = b_0 + b_1x
$$
b0是估计线性方程的纵截距,b1是估计线性方程的斜率,ŷ是在自变量x等于一个给定值的时候,y的估计值。b0和b1是对β0和β1的估计值。
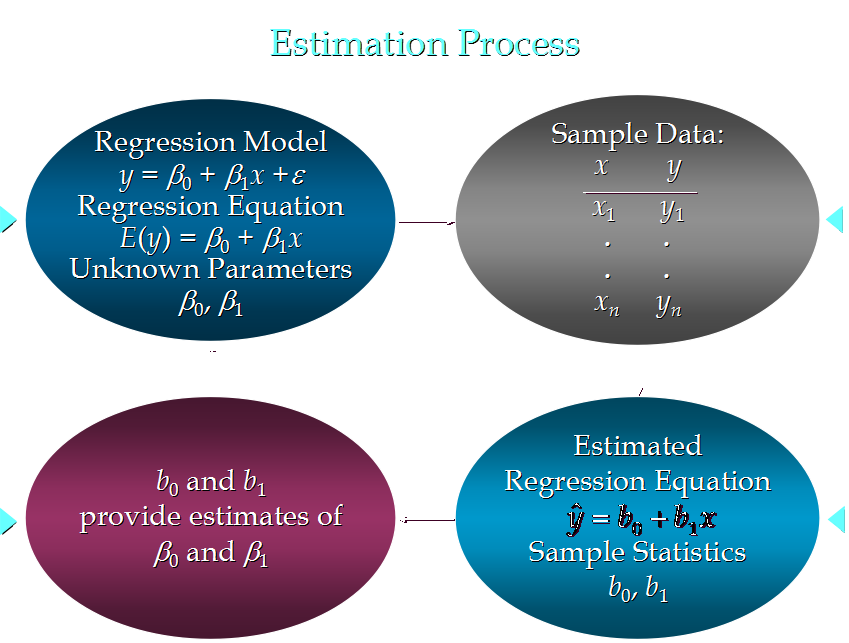
寻找的回归方程,要求与真实值的离散程度是最小的:
$$
min\sum_{i=0}^{n}(y_{i}-\widehat {y})^2
$$
$$
b_1 = \frac{\sum(x_{i}-\overline{x})(y_{i}-\overline{y})}{\sum(x_{i}-\overline{x})^2}
$$
$$
b_0 = \overline{y} - b_1\overline{x}
$$
上面方法类似于数值分析中的最小二乘法,详细推导可见https://zh.wikipedia.org/wiki/最小二乘法
代码实例
1 | #简单现行回归:只有一个自变量 y=k*x+b 预测使 (y-y*)^2 最小 |
多元线性回归
算法
当自变量有多个时,回归模型就变成了:
$$
E(y) = \beta0 + \beta_1x_1 +…+\beta_nx_n
$$
估值函数的自变量也变多:
$$
\widehat {y} = b_0 + b_1x_1+ b_2x_2+…+b_nx_n
$$
令矩阵: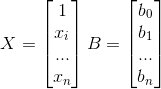
函数可以转换为:
$$
h(x) = B^TX
$$
如果有训练数据:
$$
D = (x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),…, (x^{(m)},y^{(m)}),
$$
损失函数( cost function ),寻找的目标函数应该尽可能让损失函数小,这个损失函数为:
$$
J(B) = \frac{1}{2m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})^2 = \frac{1}{2m}(XB-y)^T(XB-y)
$$
目的就是求解出一个使得代价(损失)函数最小的 B。
利用梯度下降求解估值函数
梯度下降算法是一种求局部最优解的方法,详见https://www.cnblogs.com/pinard/p/5970503.html ,今后的博客也会详细介绍。B 由多个元素组成,对于损失函数可以求偏导如下:
$$
\frac{\partial}{\partial{B_j}} = \frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_{j}^{(i)}
$$
更新B:
$$
B_{j} = B_{j} - \alpha\frac{\partial}{\partial{B_j}}J(B)
$$
其中α 表示学习率,决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。
最小二乘法求解估值函数
多元多项式的情况一样可以利用最小二乘法来进行求解,将m条数据都带入估值函数可以得到线性方程组: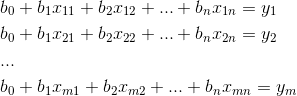
向量化后可以表示为: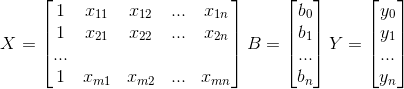
我们要让
$$
\sum_{i=1}^{m} = (y_i-\widehat{y})^2
$$
的值最小,则系数矩阵中,各个参数的偏导的值都会0,因此可以得到 n 个等式: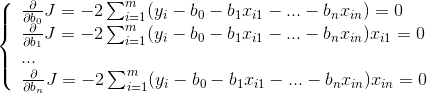
得到正规方程组: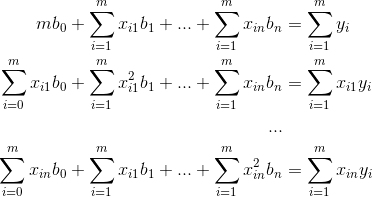
写成矩阵表示为:
$$
X^TXB = X^TY
$$
解得:
$$
B = (X^TX)^{-1}X^TY
$$
代码实例
本部分我们会用2种方式实现多元线性回归(Multiple Linear Regression ),一种是sklearn库包中自带的方法,一种是我们依据最小二乘法实现的求解方法。
应用实例:
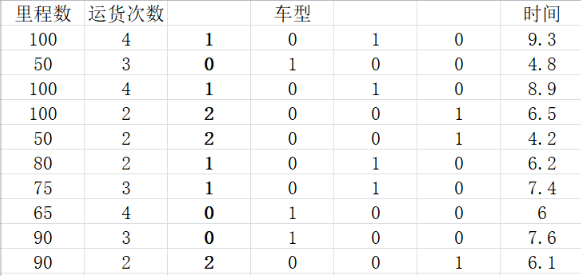
一家快递公司送货:X1: 运输里程 X2: 运输次数 Y:总运输时间
将其数据存储为csv文件如下: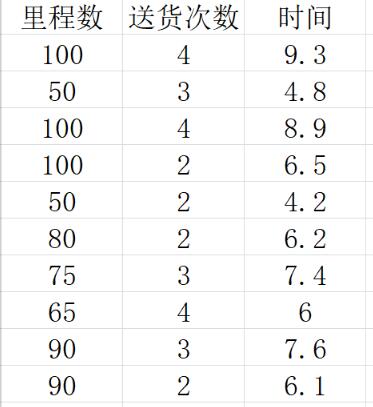
sklearn实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from numpy import genfromtxt
from sklearn import linear_model
datapath = 'G:/PycharmProjects/Machine_Learning/Linear_Regression/data1.csv'
data = genfromtxt(datapath,delimiter=',')
x = data[:,:-1]
y = data[:,-1]
# print(x)
# print(y)
mlr = linear_model.LinearRegression()
mlr.fit(x,y)
# print (mlr)
# print ("coef: " + str(mlr.coef_) )
# print ("intercept: " + str(mlr.intercept_))
x_predict = [50,3]
y1_predict = mlr.predict([x_predict])
print("y_predict: " + str(y1_predict))
#output [4.95830457]
最小二乘法实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import numpy as np
from numpy import genfromtxt
class MyLinearRegression(object):
def __init__(self):
self.b = []
def fit(self, x: list, y: list):
# 为每条训练数据前都添加 1
tmpx = [[1] for _ in range(len(x))]
for i, v in enumerate(x):
tmpx[i] += v
x_mat = np.mat(tmpx)
y_mat = np.mat(y).T
xT = x_mat.T
self.b = (xT * x_mat).I * xT * y_mat
def predict(self, x):
return np.mat([1] + x) * self.b
datapath = 'G:/PycharmProjects/Machine_Learning/Linear_Regression/data1.csv'
data = genfromtxt(datapath,delimiter=',')
x = data[:,:-1]
y = data[:,-1]
test_row = [50, 3]
linear = MyLinearRegression()
linear.fit(x, y)
print(linear.predict(test_row))
#output[ 4.95830457]
补充:
上面实例中,x的特征都是连续数值,如果有离散型的特征(车型),我们可以采取如下方法,将车型特征进行one-hot编码,代码不需要变化。