最近刷题时,经常会遇到关于L1和L2范数的知识点,本文就其详细的分析记录一下。
前言
我们常见的监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时要最小化误差。最小化误差是为了让我们的模型拟合我们的训练数据,而规则化参数是防止我们的模型过分拟合我们的训练数据。
如果参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。但训练误差小并不是我们的最终目标,我们的目标是希望模型的测试误差小,也就是能准确的预测新的样本。所以,我们需要保证模型“简单”的基础上最小化训练误差,这样得到的参数才具有好的泛化性能(也就是测试误差也小),而模型“简单”就是通过规则函数来实现的。另外,规则项的使用还可以约束我们的模型的特性。这样就可以将人对这个模型的先验知识融入到模型的学习当中,强行地让学习到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。
看待规则化的其他角度:
- 规则化符合奥卡姆剃刀
(Occam's razor)原理,也就是在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型。 - 从贝叶斯估计的角度来看,规则化项对应于模型的先验概率。
- 规则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项
(regularizer)或惩罚项(penalty term)。
一般来说,监督学习可以被看做最小化下面的目标函数: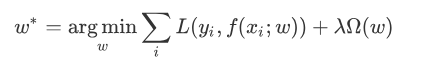
其中,第一项$L(y_{i},f(x_{i};w))$ 衡量我们的模型(分类或者回归)对第$i$个样本的预测值$f(x_{i};w)$和真实的标签$y_{i}$之前的误差。因为模型目的是拟合我们的训练样本,所以我们要求这一项最小,也就是要求我们的模型尽量的拟合我们的训练数据。但正如之前所说,我们不仅要保证训练误差最小,也更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数$w$的规则化函数$\Omega(w)$去约束我们的模型尽量的简单。
机器学习的大部分带参模型都和这个不但形似,而且神似。是的,其实大部分无非就是变换这两项而已。对于第一项Loss函数,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是集成Boosting了;如果是log-Loss,那就是 Logistic Regression了;等等。不同的loss函数,具有不同的拟合特性,这个也得就具体问题具体分析的。本文主要关注第二项“规则项Ω(w)”。规则化函数$Ω(w)$也有很多种选择,本文主要介绍L0、L1和L2范数。
L0范数与L1范数
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。换句话说,让参数W是稀疏的。但是在大多数论文中,稀疏都是通过L1范数来实现的。这是因为L0和L1有着某种不寻常的关系。那我们再来看看L1范数是什么?它为什么可以实现稀疏?为什么大家都用L1范数去实现稀疏,而不是L0范数呢?
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。 现在我们来分析为什么L1范数会使权值稀疏?有人可能会这样给你回答“它是L0范数的最优凸近似”。实际上,还存在一个更好的回答:任何的规则化算子,如果他$W_{i}=0$的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。W的L1范数是绝对值,$|w|$在$w=0$处是不可微,但这还是不够直观。这里因为我们需要和L2范数进行对比分析。
上面还有一个问题:既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。
一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
参数稀疏的好处:
特征选择(Feature Selection):
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,$x_{i}$的大部分元素(也就是特征)都是和最终的输出$y_{i}$没有关系或者不提供任何信息的,在最小化目标函数的时候考虑$x_{i}$这些额外的特征,虽然可以获得更小的训练误差(可能导致模型过拟合),但在预测新的样本时,这些没用的信息反而会被考虑(噪音),从而干扰了对正确$y_{i}$的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
可解释性(Interpretability):
另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:
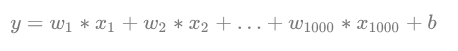
(一般为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的$w*$就只有很少的非零元素,例如只有5个非零的$wi$,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个$w_{i}$都非0,医生面对这1000种因素,累觉不爱。
L2范数
除了L1范数,还有一种更受宠幸的规则化范数是L2范数:$ ||W||_2$。它也不逊于L1范数,它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。这用的很多,因为它的强大功效是改善机器学习里面一个非常重要的问题:过拟合。至于过拟合是什么,上面也解释了,就是模型训练时候的误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,准确率很低。通俗的讲就是应试能力很强,实际应用能力很差。擅长背诵知识,却不懂得灵活利用知识。例如下图所示: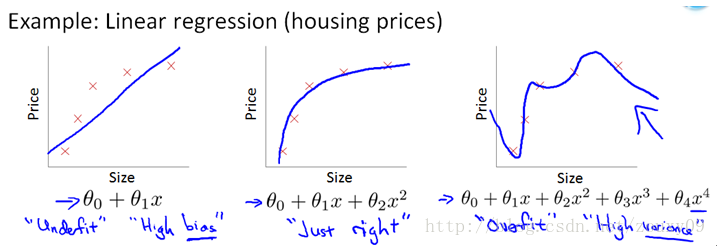
上面的图是线性回归,下面的图是Logistic回归,也可以说是分类的情况。从左到右分别是欠拟合(underfitting,也称High-bias)、合适的拟合和过拟合(overfitting,也称High variance)三种情况。可以看到,如果模型复杂(可以拟合任意的复杂函数),它可以让我们的模型拟合所有的数据点,也就是基本上没有误差。对于回归来说,就是我们的函数曲线通过了所有的数据点,如上图右。对分类来说,就是我们的函数曲线要把所有的数据点都分类正确,如下图右。这两种情况很明显过拟合了。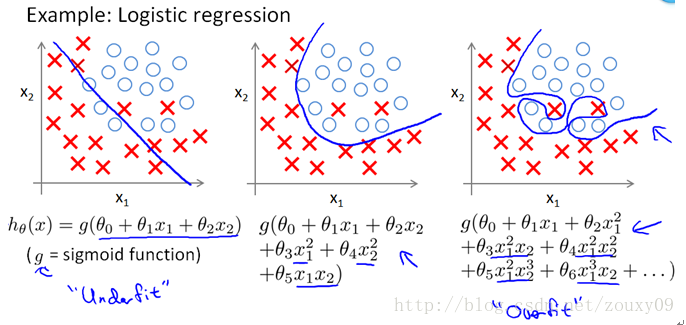
为什么L2范数可以防止过拟合?回答这个问题之前,我们得先看看L2范数的实质。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?我也不懂,我的理解是:限制了参数很小,实际上就限制了多项式某些分量的影响很小(看上面线性回归的模型的那个拟合的图),这样就相当于减少参数个数。
一句话总结下:通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。
L2范数的好处:
- 从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。
- 从优化或者数值计算的角度来说,L2范数有助于处理
condition number不好的情况下矩阵求逆很困难的问题。关于condition number,大家可以看文末的参考资料链接,里面讲的很详细。
L1和L2的差别
L1让绝对值最小,L2让平方最小,为什么会有那么大的差别呢?这里给出两种几何上直观的解析:
下降速度:
我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。(此解释待商榷)
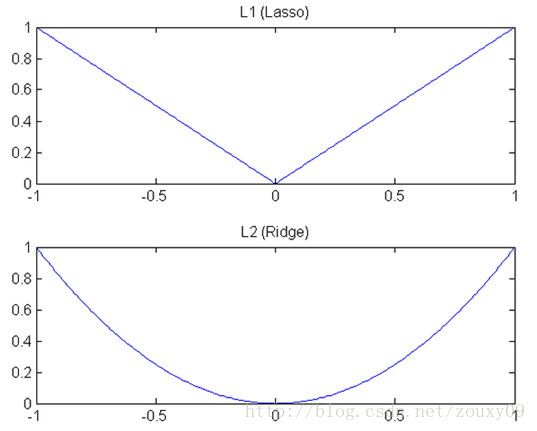
模型空间的限制(看的不是太懂):
实际上,对于L1和L2规则化的代价函数来说,我们可以写成以下形式: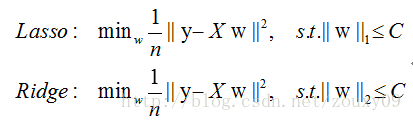
也就是说,我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:
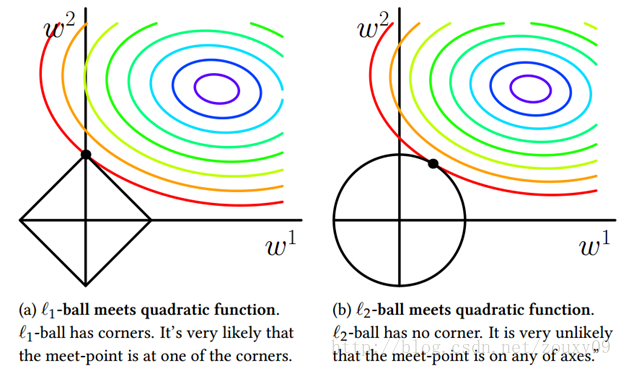
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0(稀疏),而L2会选择更多的特征,这些特征都会接近于0(平滑)。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
