昨天做完了牛客网上的机器学习试题,下面是对一些错题的分析,并简要总结了一些机器学习中应该注意的知识点,过段时间会对其中的一些方法进行更加详细的分析介绍。题中打问号?代表该题答案存在争议,不一定准确。
过拟合问题
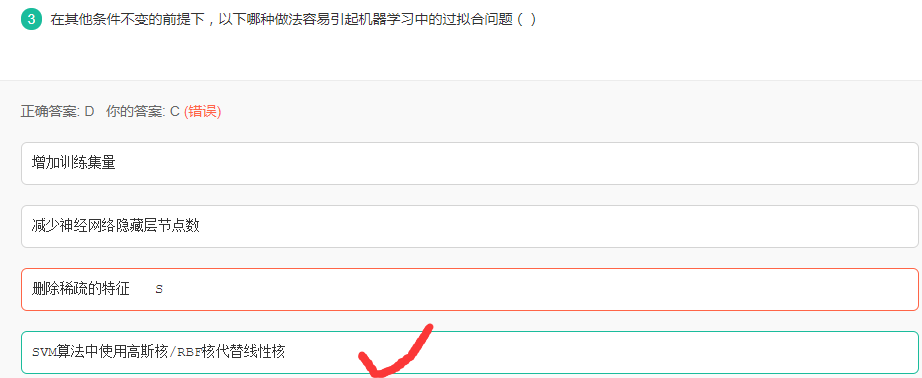
解析:
造成过拟合的原因主要有:
- 训练数据不足
- 训练模型过度导致模型非常复杂,泛化能力差
- 样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
- 权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征
- 选项A增加训练集可以解决训练数据不足的问题,防止过拟合
- 选项B对应使得模型的复杂度降低,防止过拟合
- 选项C类似主成分分析,降低数据的特征维度,使得模型复杂度降低,防止过拟合
- 选项D使得模型更加复杂化,会充分训练数据导致过拟合
条件概率
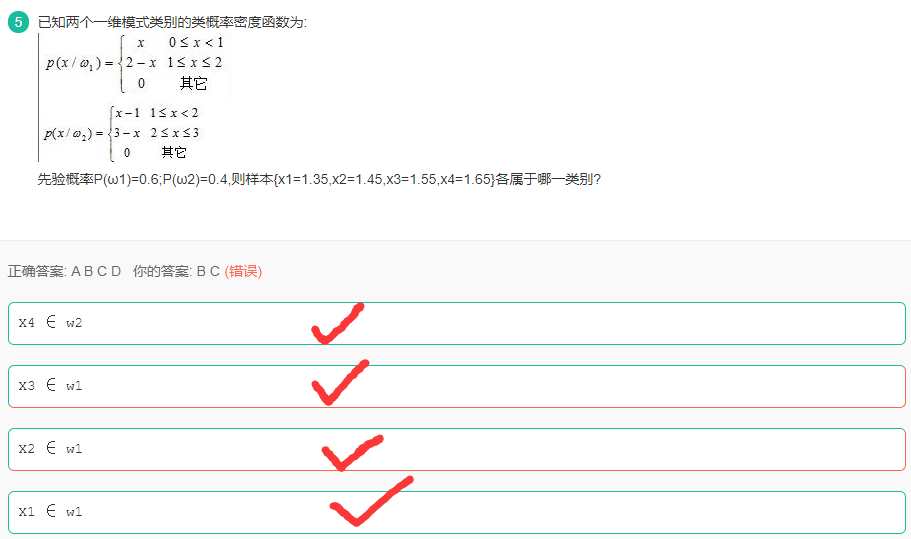
解析:
由条件概率公式可知: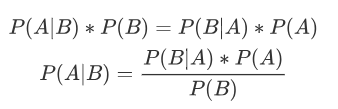

先验概率未知
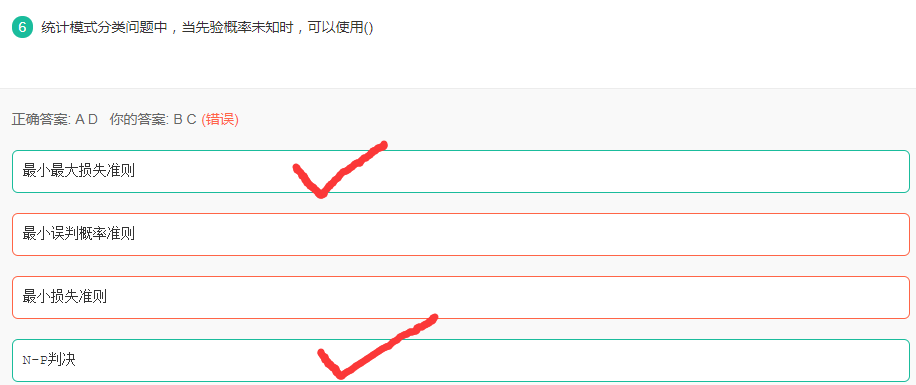
解析: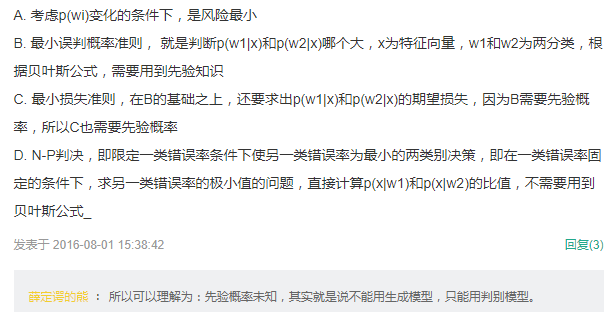
朴素贝叶斯(NB)
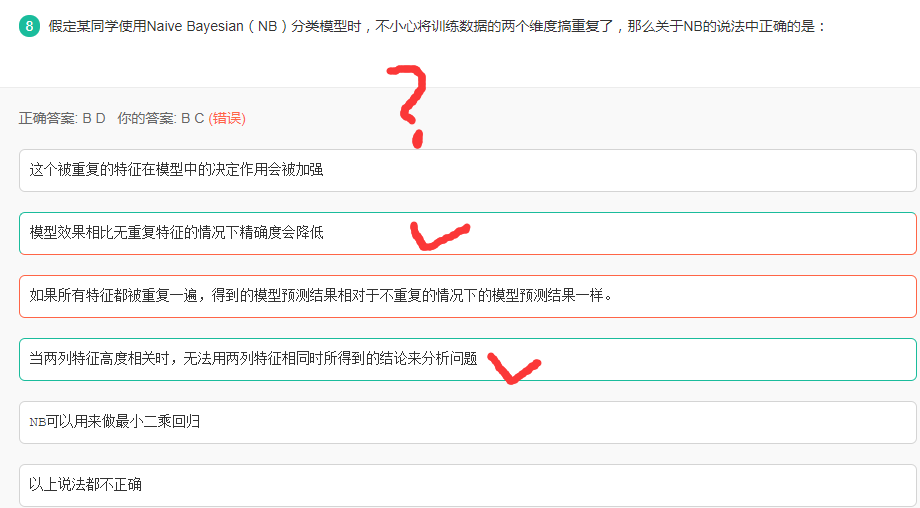
NB的核心在于它假设向量的所有分量之间是独立的。
在贝叶斯理论系统中,都有一个重要的条件独立性假设:假设所有特征之间相互独立,这样才能将联合概率拆分。
分支定界法(branch and bound)
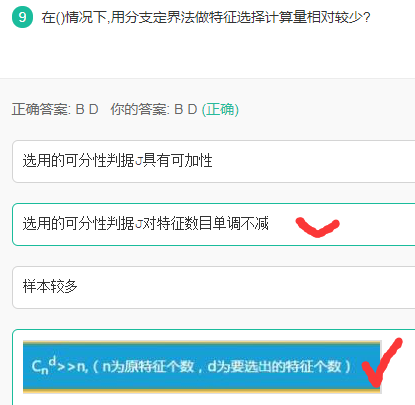
解析:
基于核的机器学习算法
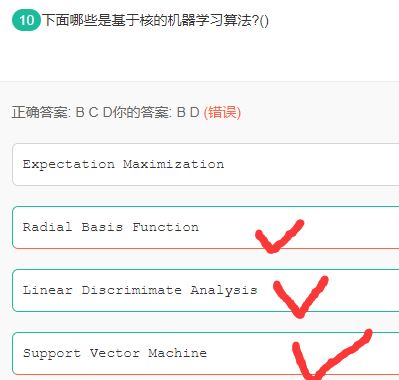
解析:
- A EM算法,聚类算法
- B 径向基核函数
- C 线性判别分析
- D 支持向量机
核函数的本质就是将一个空间转化为另一个空间的变化,线性判别分析是把高纬空间利用特征值和特征向量转化到一维空间,核化的LDA模型是KFDA。
L1和L2范数
解析:
- L1范数是指向量中各个元素的绝对值之和,也叫”系数规则算子(
Lasso regularization)。它可以实现稀疏,通过将无用特征对应的参数W置为零实现。 - L2范数是指向量各元素的平方和然后开方,用在回归模型中也称为岭回归(
Ridge regression)。L2避免过拟合的原理是:让L2范数的规则项||W||2尽可能小,可以使得W每个元素都很小,接近于零,但是与L1不同的是,不会等于0;这样得到的模型抗干扰能力强,参数很小时,即使样本数据x发生很大的变化,模型预测值y的变化也会很有限。
准确率、召回率及F1值
解析:
精准度和召回率是一对矛盾的度量,一般来说,精准度越高,召回率越低;召回率越高,精准度越低。
生成式模型和判别式模型
生成式模型(Generative Model)与判别式模型(Discrimitive Model)是分类器常遇到的概念,它们的区别在于:
对于输入x,类别标签y:
生成式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
生成式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。
公式上看
生成模型: 学习时先得到 P(x,y),继而得到 P(y|x)。预测时应用最大后验概率法(MAP)得到预测类别 y。
判别模型: 直接学习得到P(y|x),利用MAP得到 y。或者直接学得一个映射函数 y=f(x)。
直观上看
生成模型: 关注数据是如何生成的
判别模型: 关注类别之间的差别
例子:
假如你的任务是识别一个语音属于哪种语言。例如对面一个人走过来,和你说了一句话,你需要识别出她说的到底是汉语、英语还是法语等。那么你可以有两种方法达到这个目的:
- 学习每一种语言,你花了大量精力把汉语、英语和法语等都学会了,我指的学会是你知道什么样的语音对应什么样的语言。然后再有人过来对你说,你就可以知道他说的是什么语音.
- 不去学习每一种语言,你只学习这些语言之间的差别,然后再判断(分类)。意思是指我学会了汉语和英语等语言的发音是有差别的,我学会这种差别就好了。
那么第一种方法就是生成方法,第二种方法是判别方法。
常见的判别式模型:
- 逻辑回归 Logistic Regression
- 支持向量机 SVM
- 神经网络 NN
- 传统神经网络 Traditional Neural Networks
- 邻近取样 Nearest Neighbor
- 条件随机场 CRF
- 线性判别分析 Linear Discriminant Analysis
- 提升算法 Boosting
- 线性回归 Linear Regression
- 高斯过程 Gaussian Process
- 分类回归树 Classification and Regression Tree (CART)
- 区分度训练
常见的生成式模型:
- 高斯 Gaussians
- 朴素贝叶斯 Naive Bayes
- 混合多项式 Mixtures of Multinomials
- 混合高斯模型 Mixtures of Gaussians
- 多专家模型 Mixtures of Experts
- 隐马尔科夫模型 HMM
- S型信念网络 Sigmoidal Belief Networks
- 贝叶斯网络 Bayesian Networks
- 马尔科夫随机场 Markov Random Fields
- 潜在狄利克雷分配 Latent Dirichlet Allocation(LDA)
- 判别式分析
- K近邻 KNN
- 深度信念网络 DBN
聚类算法影响因素
解析:
聚类的目标是使同一类对象的相似度尽可能地大,不同类对象之间的相似度尽可能的小。
聚类分析算法主要可以分为:
- 划分法(Partitioning Methods)
- 层次法(Hierarchical Me thods)
- 基于密度的方法(Density-Based Methods)
- 基于网格的方法(Grid-Based M ethods)
- 基于模型的方法(Model-Based Methods)
- 谱聚类(Spectral Clustering)
C大约说的是度量方式,例如KMeans 可以用欧式距离啊,也可用其他的距离,这也是分类准则。(C正确) 不过个人觉得C有歧义;
特征选取的差异会影响聚类效果(A正 确)。
聚类的目标是使同一类对象的相似度尽可能地大,因此不同的相似度测度方法对聚类结 果有着重要影响(B正确)。
由于聚类算法是无监督方法,不存在带类别标签的样本,因此, D选项不是聚类算法的输入数据。
隐马尔科夫模型
解析:
- 前向后向算法解决的是一个评估问题,即给定一个模型,求某些特定观测序列的概率,用于评估该序列最匹配的模型。
- Baum-Welch算法解决的是一个模型训练问题(学习),即参数估计,是一种无监督的训练方法,主要通过EM迭代实现。
- 维特比算法解决的是一个预测问题,通信中的解码问题,即给定一个模型和某个特定的输出序列,求最可能产生这个输出的状态序列。比如通过海藻变化(输出序列)来观测天气(状态序列)。
AdaBoost及SVM
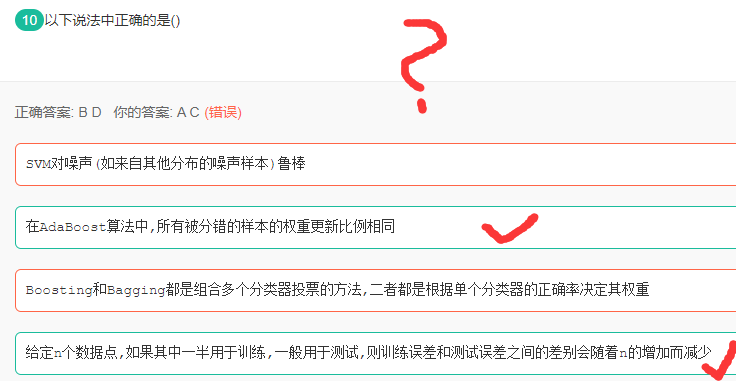
解析:
卷积大小计算

解析:
特征选择方法
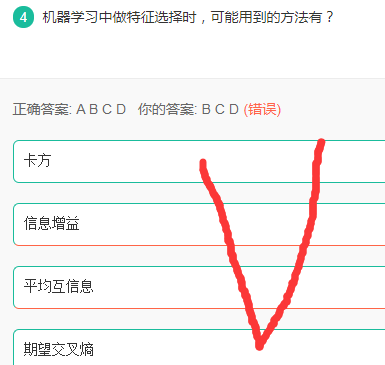
解析:
缺失值处理方法
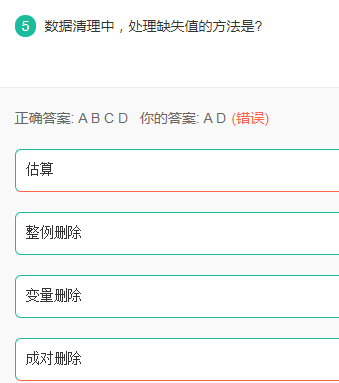
解析:
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
- 估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。
- 整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
- 变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
- 成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。
信息增益

解析:
本题主要考察信息增益的计算方式,具体可参考我之前博客决策树:
$$
Gain(A) = Info(D) - InfoA(D)
$$
其中Info表示信息熵,计算公式如下: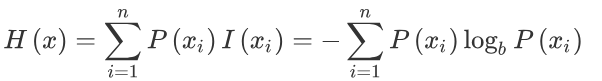
所以可以计算出各特征的信息增益如下所示: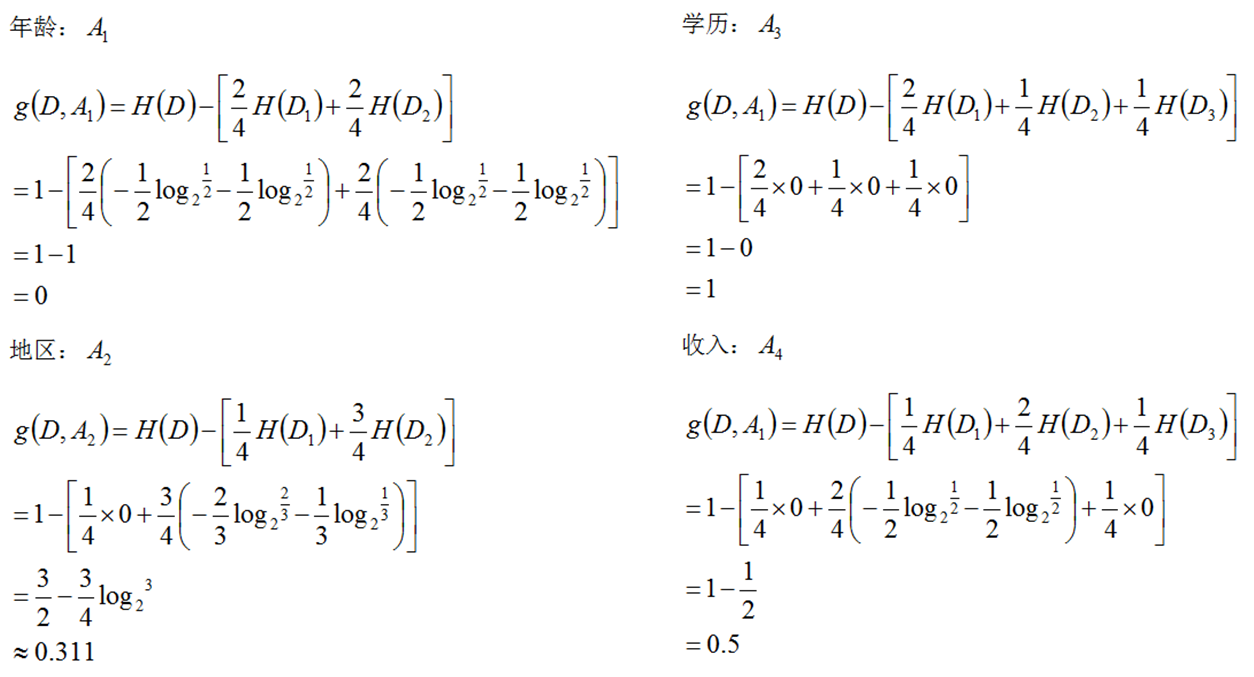
置信度及支持度
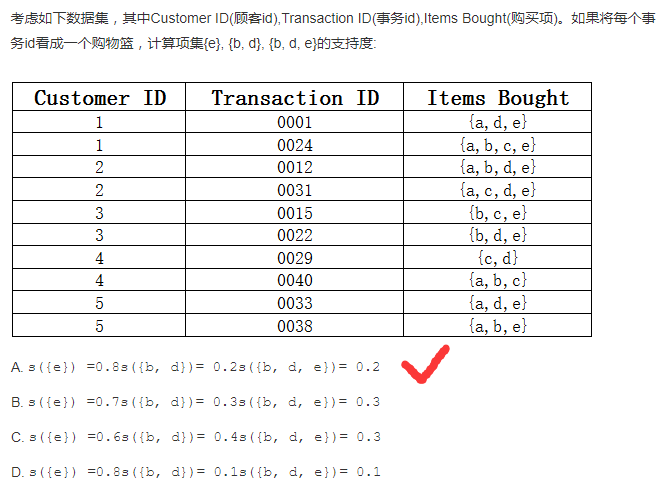
解析:
置信度计算规则为: 同时购买商品A和商品B的交易次数/购买了商品A的次数
支持度计算规则为: 同时购买了商品A和商品B的交易次数/总的交易次数
求解线性不可分方法
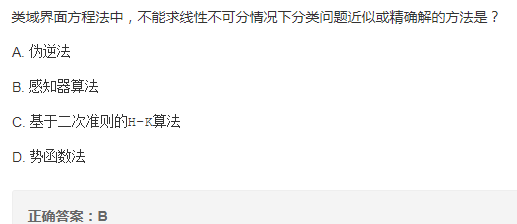
解析:
伪逆法: 径向基(RBF)神经网络的训练算法,径向基解决的就是线性不可分的情况。
感知器算法: 线性分类模型。
H-K算法: 在最小均方误差准则下求得权矢量,二次准则解决非线性问题。
势函数法: 势函数非线性。
时间序列模型
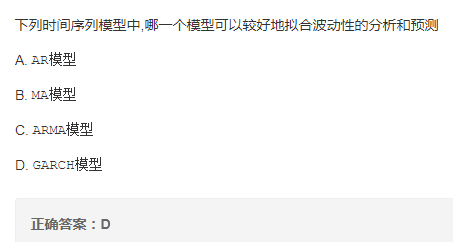
解析:
AR模型:自回归模型,是一种线性模型
MA模型:移动平均法模型,其中使用趋势移动平均法建立直线趋势的预测模型
ARMA模型:自回归滑动平均模型,拟合较高阶模型
GARCH模型:广义回归模型,对误差的方差建模,适用于波动性的分析和预测
PMF PDF CDF

解析:
CRF(条件随机场)
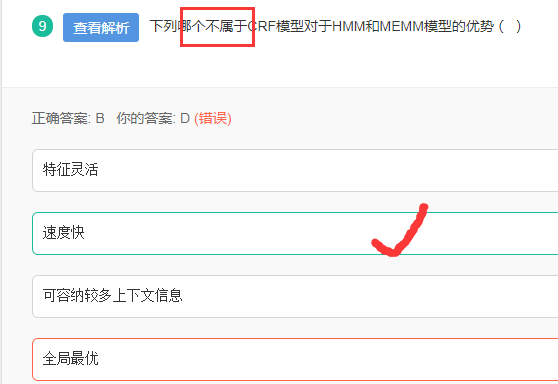
解析:
HMM(隐马尔科夫模型):HMM是一种产生式模型,定义了联合概率分布p(x,y) ,其中x和y分别表示观察序列和相对应的标注序列的随机变量。它包含2个基本假设:
- 后一个隐藏状态只依赖于前一个隐藏状态。
- 观测值之间相互独立,观测值只依赖于该时刻的马尔科夫链的隐状态。
缺点:1. HMM只依赖于每一个状态和它对应的观察对象:2、目标函数和预测目标函数不匹配:
MEMM(最大熵马尔科夫模型):最大熵马尔科夫模型把HMM模型和
Maximum Entropy模型的优点集合成一种生成模型(Generative Model)。克服了观察值之间严格独立产生的问题,但仍存在标注偏置问题(Label bias problem)。- CRF(条件随机场):CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设,当然,模型相应得也变复杂了。MEMM是局部归一化,CRF是全局归一化。
CRF 的优点:特征灵活,可以容纳较多的上下文信息,能够做到全局最优
CRF 的缺点:速度慢总结:三者都是NLP(自然语言处理)中的基础语言模型。
线性回归描述
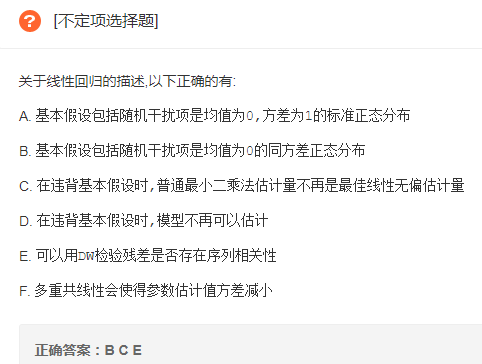
解析:


K-L与PCA
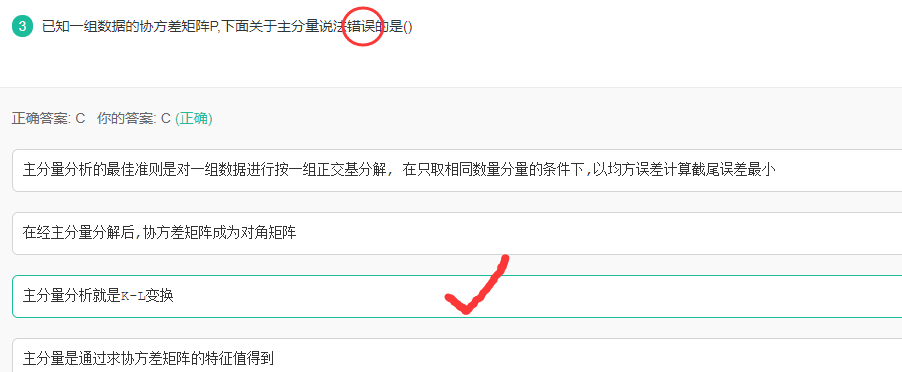
解析:
K-L变换与PCA变换是不同的概念,PCA的变换矩阵是协方差矩阵,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内离散度矩阵等等)。当K-L变换矩阵为协方差矩阵时,等同于PCA。
数据不均衡

解析:
- 重采样。
A可视作重采样的变形。改变数据分布消除不平衡,可能导致过拟合。 - 欠采样。
C的方案 提高少数类的分类性能,可能丢失多数类的重要信息。 - 权值调整。
D方案也是其中一种方式。
HK算法与感知器
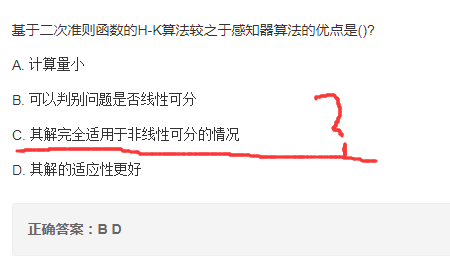
解析:
时间序列算法模型

解析:
常见的时间序列算法模型有
- 移动平均法 (MA) 简单移动平均法
- 自回归模型(AR)
- 自回归滑动平均模型(ARMA)
- GARCH模型 指数平滑法
ABD都是一些关于股票涨跌的分析方法。
SVM核函数
解析:
SVM核函数包括:
线性核函数、多项式核函数、径向基核函数(RBF)、高斯核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数。
Logit与SVM
解析:
A. Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。A错误
B. Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确
C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化,正确。
D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。(个人觉得但最好是加上正则项吧)
LDA与PCA
LDA(线性判别分析)用于降维,和PCA(主成分分析)有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
相同点:
- 两者均可以对数据进行降维。
- 两者在降维时均使用了矩阵特征分解的思想。
- 两者都假设数据符合高斯分布。
不同点:
- LDA是有监督的降维方法,而PCA是无监督的降维方法
- LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- LDA除了可以用于降维,还可以用于分类。
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向
常见的数据降维方法
线性
- LDA(线性判别分析)
- PCA(主成分分析)
非线性
- 核方法(KPCA、KFDA等)
- 二维化
- 流行学习(LLE、LPP、ISOMap等)
其他方法:
- 神经网络(自编码)
- 聚类
3.小波分析- LASSO(参数压缩)
- SVD奇异值分解
线性分类器准则

解析:
线性分类器有三大类:感知器准则函数、SVM、Fisher准则,而贝叶斯分类器不是线性分类器。
- 感知器准则函数:代价函数
J=-(W*X+w0),分类的准则是最小化代价函数。感知器是神经网络(NN)的基础。- SVM:支持向量机也是很经典的算法,优化目标是最大化间隔(margin),又称最大间隔分类器,是一种典型的线性分类器。(使用核函数可解决非线性问题)
- Fisher准则:更广泛的称呼是线性判别分析(LDA),将所有样本投影到一条远点出发的直线,使得同类样本距离尽可能小,不同类样本距离尽可能大,具体为最大化“广义瑞利商”。
贝叶斯分类器:一种基于统计方法的分类器,要求先了解样本的分布特点(高斯、指数等),所以使用起来限制很多。在满足一些特定条件下,其优化目标与线性分类器有相同结构(同方差高斯分布等),其余条件下不是线性分类。
